Chapter 5: Design Consistent Hashing
Consistent hashing is a key technique in distributed systems to ensure minimal data movement when servers are added or removed.
The Rehashing Problem
-
Common Way and Problem
-
If you have n cache servers, a common way to balance the load is to use the following hash method:
serverIndex = hash(key) % N, where N is the size of the server pool. -
EX: serverIndex = hash(key) % 4
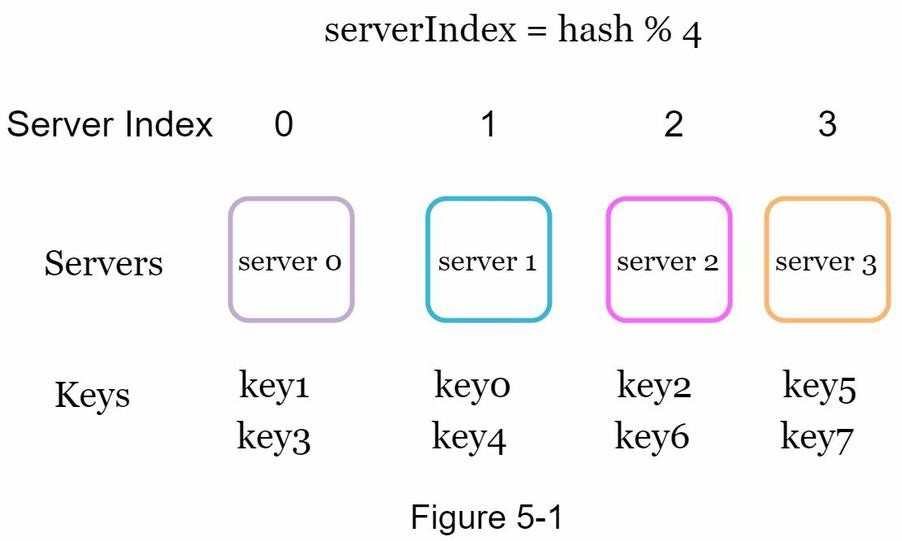
-
Problem: If server 1 goes offline and we re-distribute? (ex:hash for key0, key1, key2, key3 = 9, 0, 10, 8...)
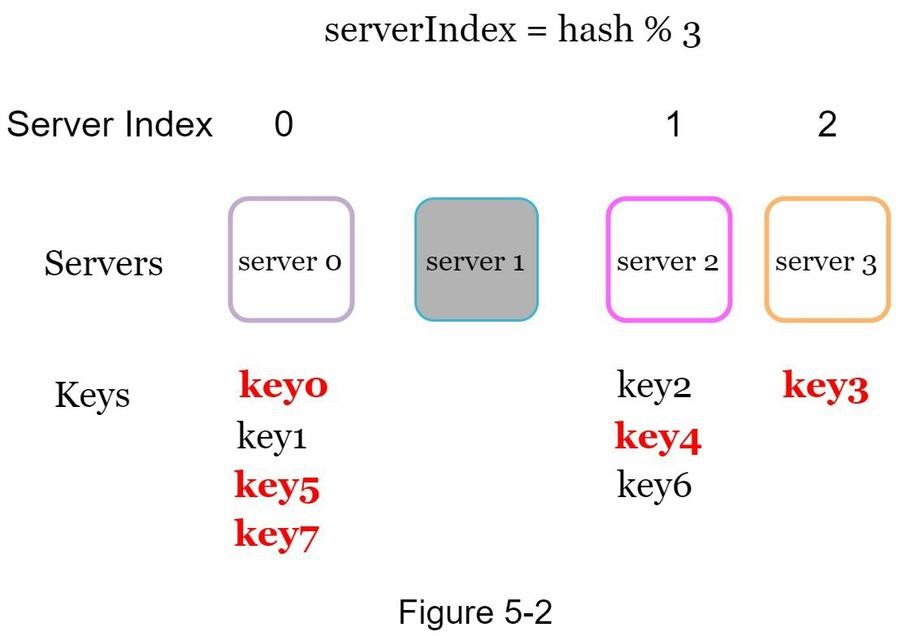
→ Since the modulo base changes from 4 to 3, most of the keys are reassigned to different servers, not just the ones originally mapped to server 1. This leads to a large number of cache misses!
Cache Misses:
A cache miss occurs when the data requested by a system is not found in the cache, so the system has to fetch the data from a slower, underlying source, such as a database or remote server, increasing latency and reducing performance.Operation 0 1 2 3 4 5 6 7 8 9 10 11 12 key % 4 0 1 2 3 0 1 2 3 0 1 2 3 0 key % 3 0 1 2 0 1 2 0 1 2 0 1 2 0 -
Consistent hashing
-
Hash space and hash ring
- The concept of consistent hashing maps all hash values onto a circular space, also called a hash ring.
- Using a hash function like SHA-1, the output range of the hash function
fspans from0to2¹⁶⁰ - 1, forming a complete hash space. - In this example: -
x0 = 0-xn = 2¹⁶⁰ - 1- All hash values fall within this range and are treated as positions on the ring.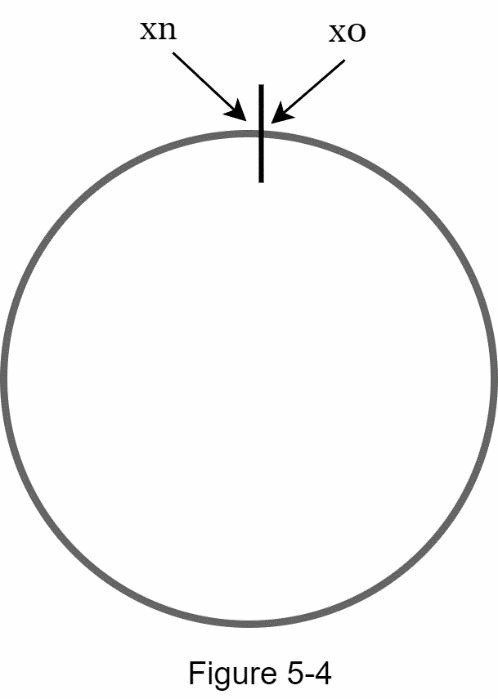
-
Hash Servers
- Next, we hash each server’s IP or name using the same hash function
f, and map each server onto the hash ring. - Each server is placed at a position on the ring, and it becomes responsible for all keys that fall between its position and the next server in the clockwise direction.
- In the example, four servers (
server0toserver3) are mapped onto the ring. - Each point
s0tos3on the ring represents the hash result of the corresponding server.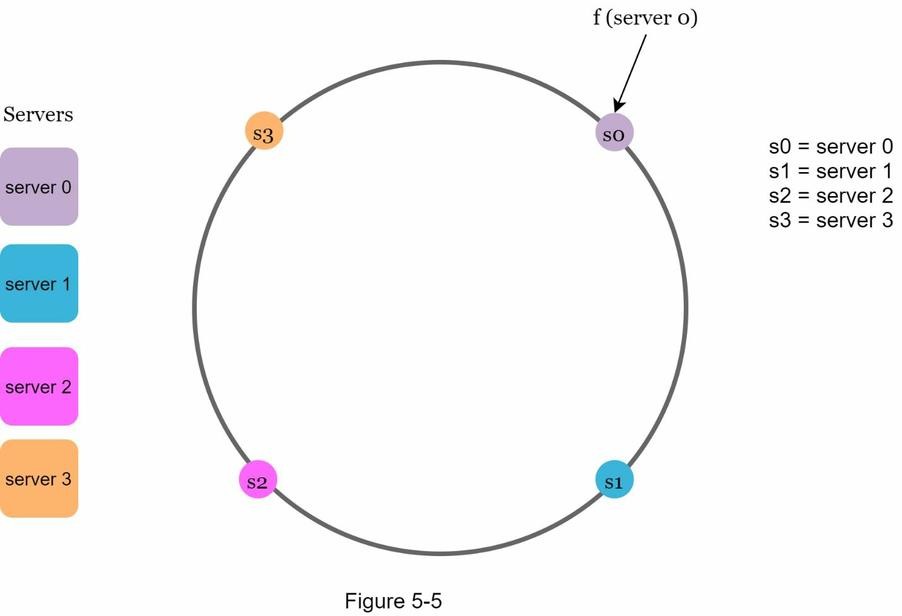
- Next, we hash each server’s IP or name using the same hash function
-
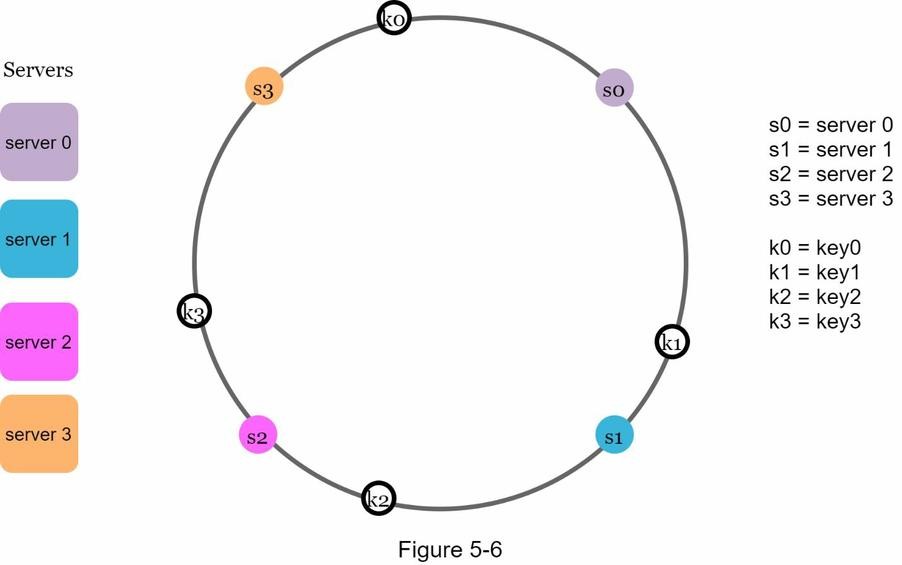
Hash Keys
- Instead of using modulo (
%) like traditional hashing, consistent hashing maps both servers and keys onto a circular hash ring. - In the example, 4 cache keys (
key0,key1,key2,key3) are hashed onto the ring using a hash function, such as SHA-1. - This avoids the rehashing problem because there is no modular operation, and key placement depends on its position on the ring.
- Instead of using modulo (
-
Server Lookup
- To determine which server a key maps to, we go clockwise from the key’s position on the ring until a server is found.
- In the example:
key0→server0key1→server1key2→server2key3→server3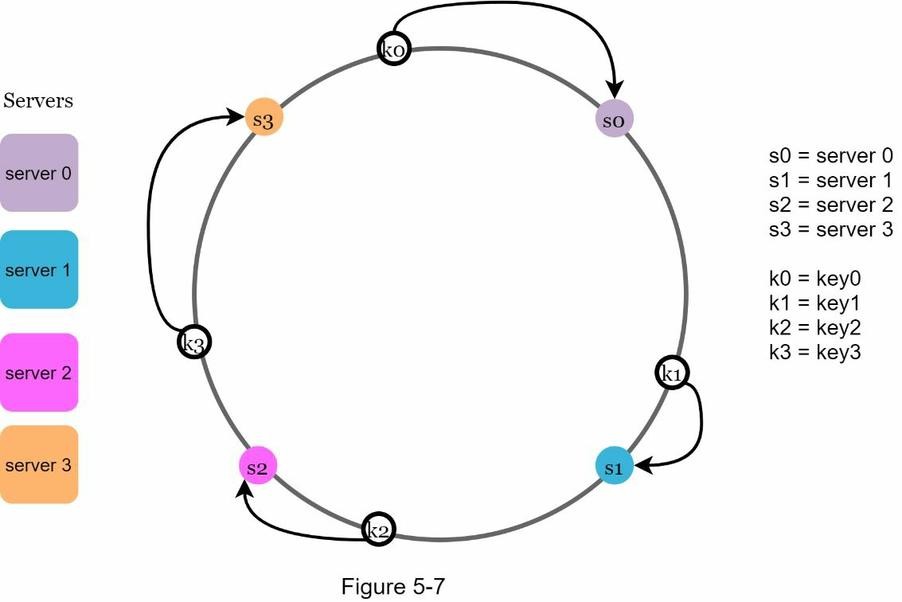
-
Add a Server!!
- Using consistent hashing, only a small portion of keys need to be reassigned when a new server is added.
- In the diagram (Figure 5‑8),
server 4is added to the hash ring. - Previously,
key0was mapped toserver 0. - After the new server is added,
key0now maps toserver 4(the next node in the clockwise direction).- ✅ Only
key0is redistributed. - ✅ Other keys (
key1,key2,key3) stay on their original servers.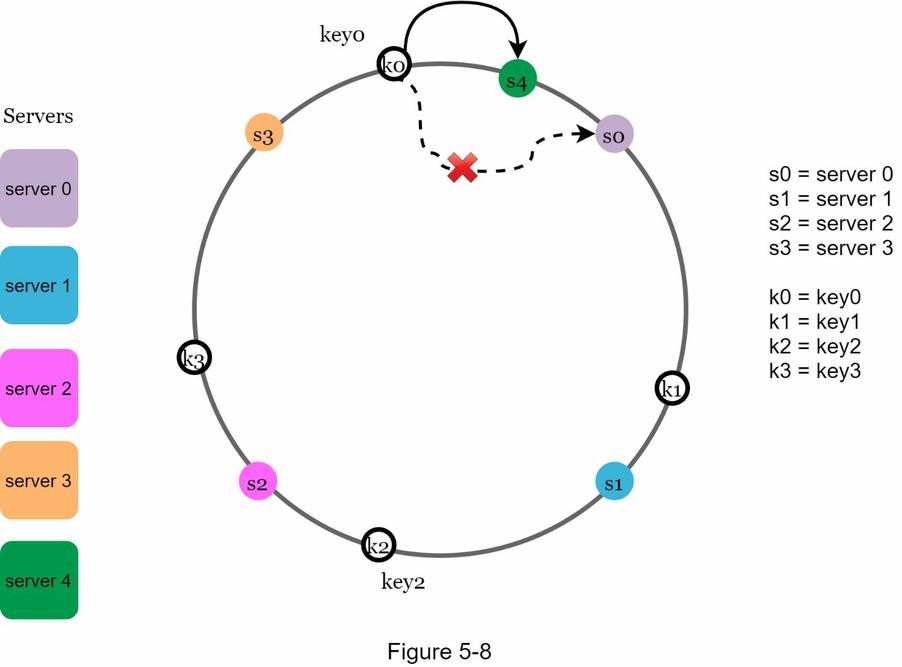
- ✅ Only
-
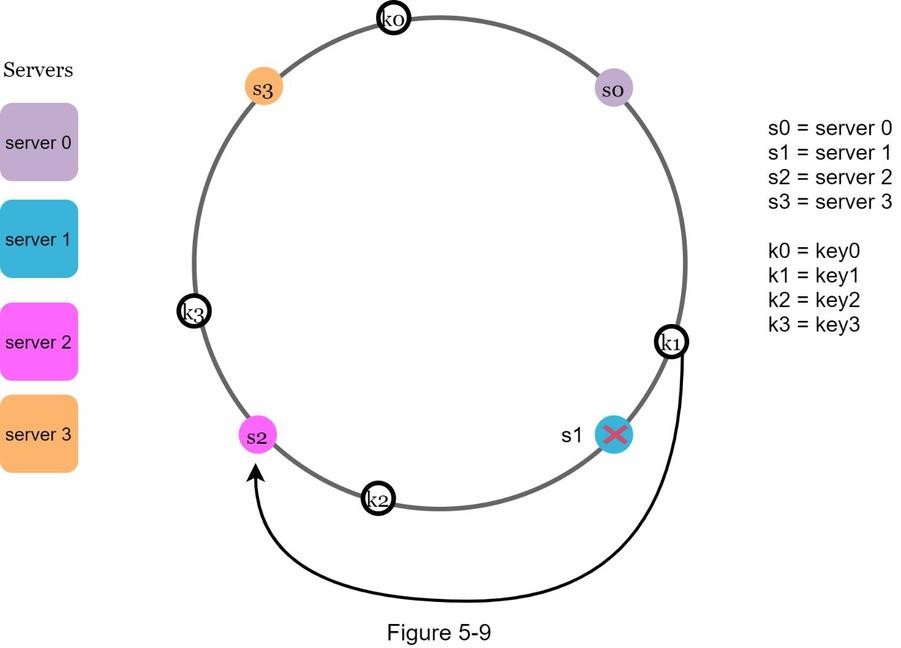
Remove a Server!!
- When a server is removed, only the keys that map to it need to be reassigned.
- In the diagram (Figure 5‑9),
server 1is removed. key1, which originally mapped toserver 1, must now be remapped.- It goes to the next server in the clockwise direction —
server 2.- ✅ Only
key1is reassigned. - ✅ All other keys are unaffected.
- ✅ Only
- This efficient redistribution is one of the core benefits of consistent hashing.
Two Issues in the Basic Consistent Hashing Approach
-
Issue 1: Uneven Partition Size After Server Removal
- When a server is removed, the partition (hash range between adjacent servers) may become uneven.
- In Figure 5-10,
server 1 (s1)is removed. As a result,server 2 (s2)takes over the entire space betweens0ands2, which is twice as large as the space ofs0ands3. - This creates a load imbalance because some servers are responsible for much larger key ranges than others.
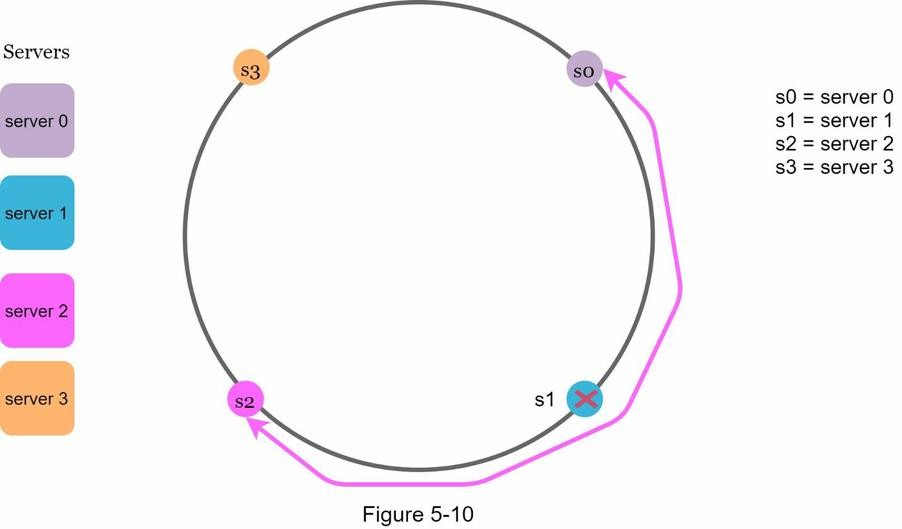
-
Issue 2: Non-Uniform Key Distribution
- Even if the partition size is balanced, key distribution may still be skewed.
- In Figure 5-11, although 4 servers (
s0tos3) are placed on the ring, most keys fall into the range ofserver 2 (s2). Serverss1ands3hold no data at all. - This happens because the positions of servers on the ring are not evenly spaced, causing some servers to receive almost all the traffic.
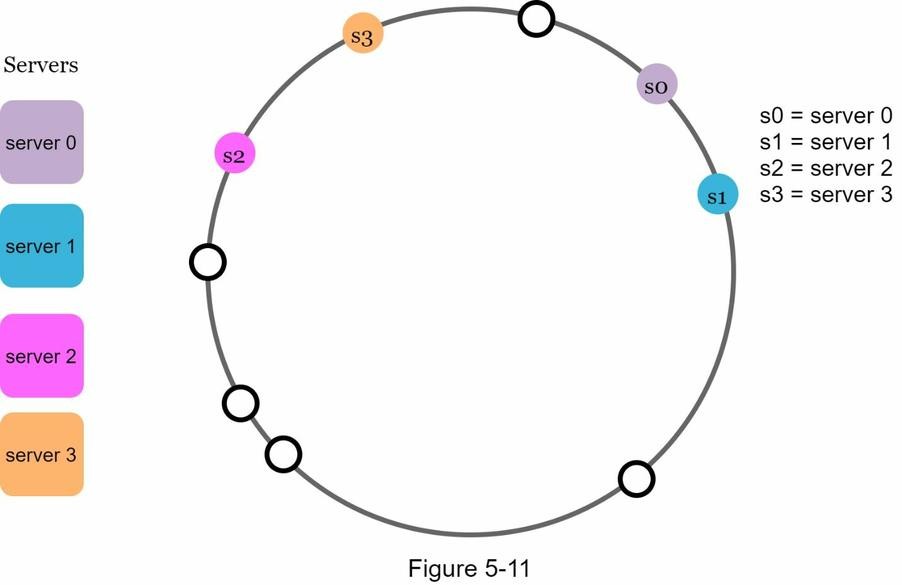
Virtual Nodes in Consistent Hashing
A virtual node refers to a logical representation of a real server. Each server is mapped to multiple positions on the hash ring to improve load balancing.
-
Why Use Virtual Nodes?
- Real servers (e.g.,
server 0,server 1) are represented by multiple virtual nodes (e.g.,s0_0,s0_1,s0_2). - This ensures a more uniform distribution of keys, even if servers are unevenly spaced.
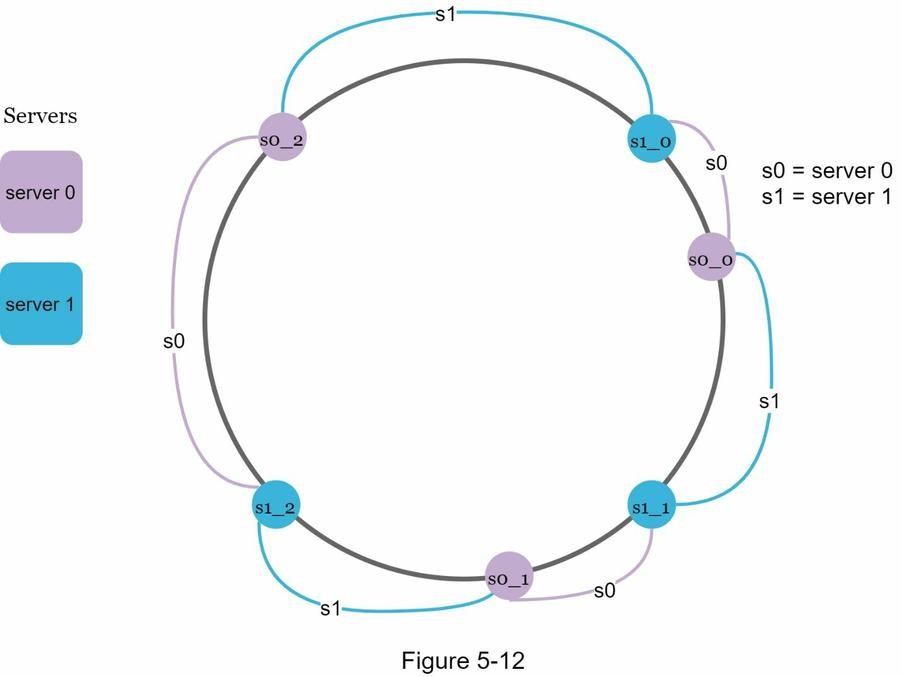
- Real servers (e.g.,
-
Key Lookup with Virtual Nodes
- Move clockwise from the key's hash position.
- Select the first virtual node encountered.
- That virtual node maps to a real server.
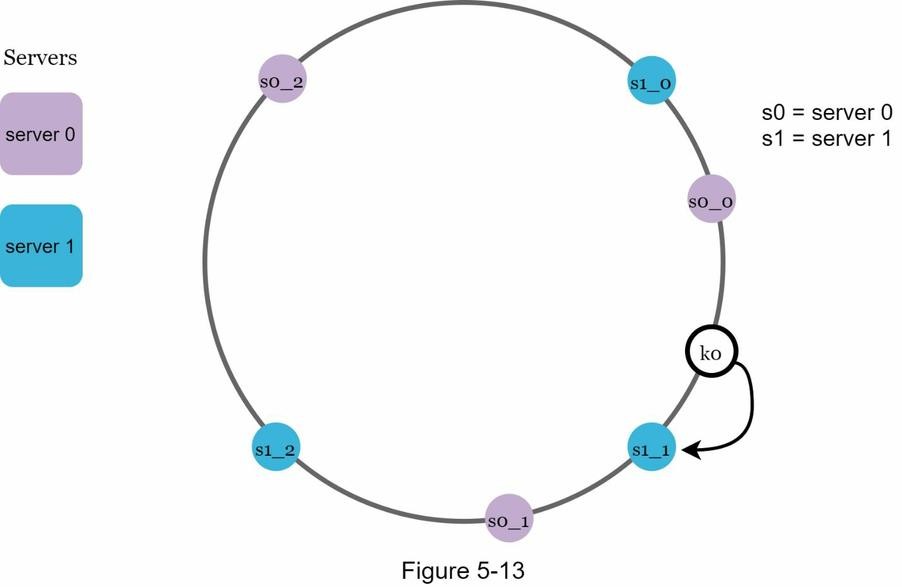
-
Balanced Load Distribution
- As the number of virtual nodes increases, key distribution becomes more even.
- Standard deviation of load:
- ~10% with 100 virtual nodes
- ~5% with 200 virtual nodes
- Trade-off: More virtual nodes = better balance, but higher metadata/storage overhead.
Find Affected Keys in Consistent Hashing
When a server is added or removed, a portion of the key space must be redistributed.
-
Adding a Server
- Start from
s4(newly added server) - Move anticlockwise around the ring
- Stop at the next encountered server (
s3) - Keys between
s3ands4are reassigned tos4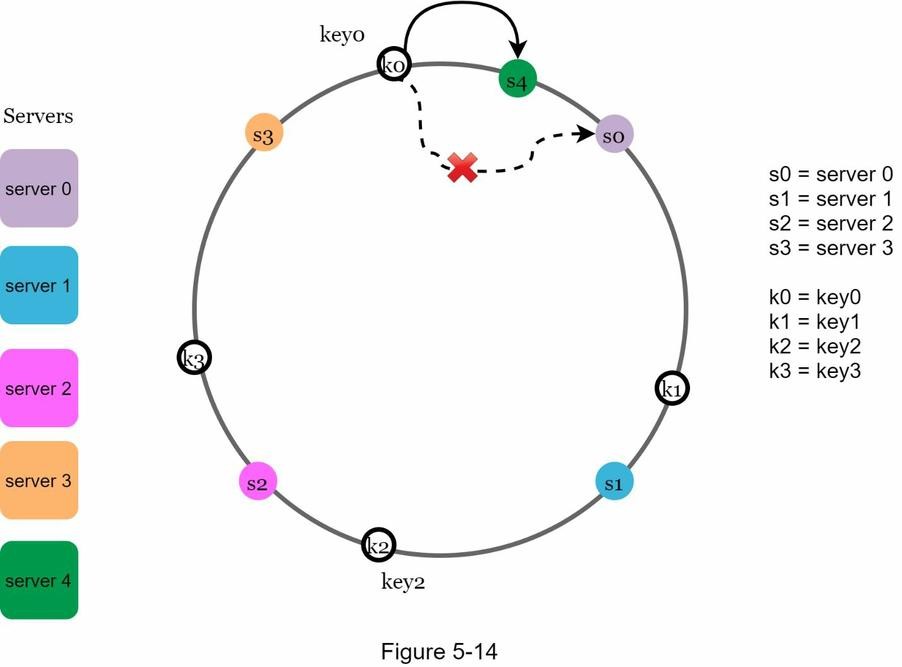
- Start from
-
Removing a Server
- Start from
s1 - Move anticlockwise until reaching
s0 - Keys between
s0ands1must be reassigned tos2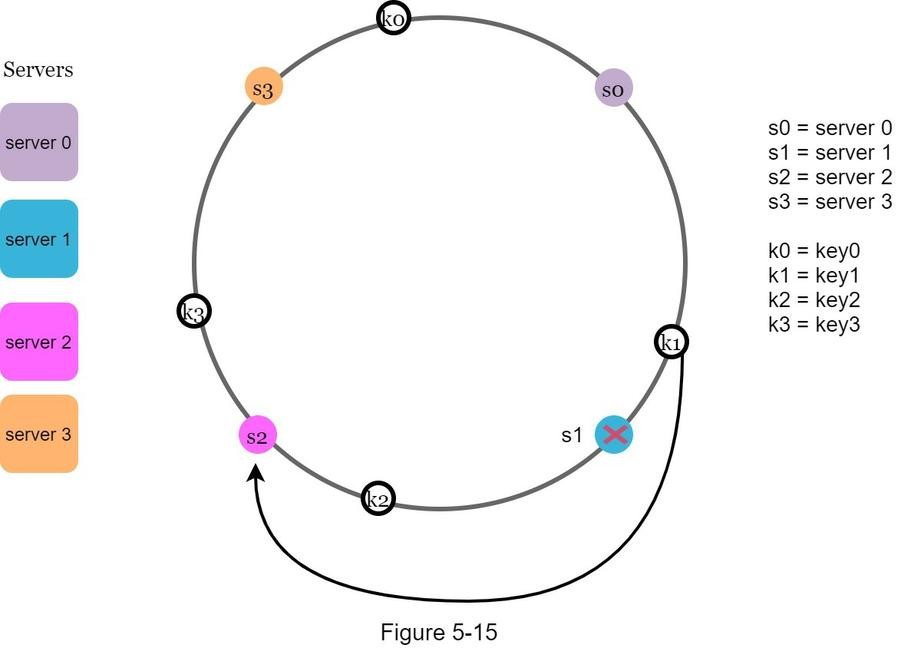
- Start from
Wrap Up: Consistent Hashing Summary
In this chapter, we explored consistent hashing in depth — its necessity and how it works.
-
Benefits of Consistent Hashing
- Minimized key redistribution when servers are added or removed.
- Horizontal scalability is easy because data is more evenly distributed.
- Hotspot mitigation: Prevents overload on a single shard.
- e.g., Imagine Katy Perry, Justin Bieber, and Lady Gaga all being routed to one server — that’s a problem!
- Virtual Nodes helps spread such hot keys more evenly.
-
Real-World Use Cases
- Amazon DynamoDB (Partitioning component)
- Apache Cassandra (Data partitioning across the cluster)
- Discord (Chat application)
- Akamai (Content Delivery Network)
- Maglev (Google’s network load balancer)
Content Review
What is a hash ring in consistent hashing?
What is the main issue with using hash(key) % N for server selection in distributed systems?
Why does consistent hashing minimize the number of keys that need to be remapped when a server is added or removed?
How do you find the server responsible for a given key in a consistent hash ring?
In a consistent hash ring, what happens when a server is removed? How is key reassignment handled?
How do we determine which keys are affected when adding a new server to the hash ring?
Why can removing a server from the consistent hash ring cause load imbalance?
How do virtual nodes help solve the uneven key distribution problem in consistent hashing?
What trade-offs are introduced when increasing the number of virtual nodes per server?