Chapter 4: Design a Rate Limiter
A rate limiter is a crucial component in any distributed system. Its primary function is to control the traffic rate for requests sent to a service. In simple terms, it sets a cap on how many times a user, device, or IP address can perform an action within a specific time frame.
Why Do We Need It?
- Prevent DoS Attacks & Resource Starvation: A rate limiter is the first line of defense against both intentional and unintentional Denial of Service (DoS) attacks. By blocking excessive requests, it ensures the service remains available for legitimate users. For example, Twitter limits tweets to 300 per 3 hours.
- Reduce Costs: Limiting requests directly translates to lower operational costs. This is critical for services that rely on paid third-party APIs (e.g., for payment processing or credit checks) and for managing cloud resource consumption.
- Prevent Server Overload: It acts as a filter to prevent backend servers from being overwhelmed by traffic spikes, whether from misbehaving bots or legitimate but high-volume users. This ensures system stability.
Understand the Problem & Establish Design Scope
This phase is about asking clarifying questions to transform a vague request like "Design a Rate Limiter" into a concrete set of requirements. The dialogue between the candidate and interviewer is key.
Requirements Summary
Based on the initial discussion, the core requirements for our system are:
- Accuracy: It must effectively limit requests according to defined rules.
- Low Latency: It should not add significant overhead to the HTTP response time.
- Memory Efficiency: It must operate with a small memory footprint.
- Distributed: The solution must work across multiple servers.
- Clear Exception Handling: Throttled users must be clearly informed (e.g., via HTTP status code
429). - High Fault Tolerance: If the rate limiter fails, it should not bring down the entire system (fail-open vs. fail-closed).
High-Level Design - Placement and Architecture
Once the requirements are clear, the next step is to outline the high-level architecture. A fundamental first decision is where the rate limiter logic should live.
Where to Put the Rate Limiter?
There are three primary locations to implement a rate limiter, each with significant trade-offs.
-
Client-Side: Implementation is done directly in the frontend application.
- Pro: Can provide immediate feedback to the user.
- Con: Completely unreliable for security. A malicious actor can easily bypass client-side logic and directly attack your servers. It should never be the only line of defense.
-
Server-Side (In the Application): The logic is embedded directly within the API server's code.
- Pro: It's reliable and secure as it's under your control.
- Con: It couples the rate-limiting logic with the business logic. If you have multiple services, you might duplicate this logic across all of them, leading to maintenance issues.
-
Middleware (API Gateway): The logic is placed in a separate layer that sits in front of your API servers. This is the most common and recommended approach in modern architectures.

- Pro:
- Decoupling: Keeps rate-limiting concerns separate from your application services.
- Centralized Control: Manage rules for all your services in one place.
- Efficiency: Services like API Gateways are often highly optimized for this kind of traffic management.
- Con: Introduces another component to manage (though often this is a managed cloud service).
How to Choose? General Guidelines
The "right" choice depends on your specific context. Consider these factors:
- Existing Tech Stack: Are you already using a microservices architecture with an API Gateway? If so, adding rate limiting there is a natural fit.
- Control vs. Convenience: Implementing it yourself gives you full control over the algorithm. Using a third-party gateway might limit your choices but is much faster to deploy.
- Engineering Resources: Building a robust, distributed rate-limiting service from scratch is a significant undertaking. If resources are limited, a commercial or managed solution is often the better business decision.
Deep Dive into Rate-Limiting Algorithms
Choosing the right algorithm is crucial as it directly impacts the accuracy, performance, and memory usage of the rate limiter. Here's a breakdown of the most common algorithms and their trade-offs.
1. Token Bucket Algorithm
This is one of the most widely used and versatile algorithms.

- How it Works:
- A bucket with a fixed capacity is created.
- Tokens are added to the bucket at a constant
refill rate. - If the bucket is full, new tokens are discarded.
- Each incoming request must consume one token from the bucket to pass.
- If the bucket is empty, the request is rejected.
- Key Idea: It allows for bursts of traffic. As long as there are tokens in the bucket, a quick succession of requests can pass. The
bucket sizedefines the maximum burst size. - Parameters:
bucket_size,refill_rate. - Pros:
- Easy to implement.
- Memory efficient.
- Flexible; allows for short-term bursts, which is good for user experience.
- Cons:
- Tuning the two parameters (
bucket_sizeandrefill_rate) can be challenging to get just right for the specific use case.
- Tuning the two parameters (
2. Leaky Bucket Algorithm
This algorithm focuses on smoothing out the request rate.

- How it Works:
- Requests are added to a First-In-First-Out (FIFO) queue upon arrival.
- The system processes requests from the queue at a fixed, constant rate.
- If the queue is full, new incoming requests are discarded.
- Key Idea: It enforces a stable outflow rate, regardless of how bursty the inflow is. It smooths out traffic spikes.
- Parameters:
bucket_size(queue size),outflow_rate. - Pros:
- Memory efficient due to fixed queue size.
- Guarantees a stable, predictable load on the downstream services.
- Cons:
- Inflexible. A burst of traffic can fill the queue, causing recent requests to be dropped even if the average rate is low. It doesn't handle legitimate bursts well.
3. Fixed Window Counter Algorithm
A simple but less accurate approach.

- How it Works:
- The timeline is divided into fixed windows (e.g., 1-minute intervals).
- Each window has a counter.
- Each request increments the counter for the current window.
- If the counter exceeds the limit, requests are dropped until the next window begins.
- Key Flaw: Edge/Boundary Problem. A burst of traffic at the boundary of two windows can allow up to 2x the limit to pass through in a real-time window. (e.g., if the limit is 100/min, a user could send 100 requests at 1:00:59 and another 100 at 1:01:01).
- Pros:
- Easy to understand and implement.
- Memory efficient (only needs one counter per key).
- Cons:
- The boundary problem can lead to inaccurate rate limiting.
4. Sliding Window Log Algorithm
This algorithm fixes the flaws of the Fixed Window approach with high precision.

- How it Works:
- It tracks the timestamp of every single request in a log (e.g., a Redis sorted set).
- When a new request arrives, it removes all timestamps from the log that are older than the current window size.
- It then counts the number of remaining timestamps in the log. If the count is below the limit, the request is accepted and its timestamp is added to the log.
- Pros:
- Very accurate. It perfectly enforces the rate limit over any sliding time window.
- Cons:
- High memory consumption. Storing a timestamp for every request can be very memory-intensive, especially for high-traffic services.
5. Sliding Window Counter Algorithm
A hybrid approach that offers a good balance between accuracy and efficiency.

- How it Works: It approximates the count in the sliding window. A common method is:
- Track counters for the current and previous time windows.
- When a new request arrives, estimate the number of requests in the rolling window by taking a weighted sum of the two counters.
- Formula:
count_in_current_window + (count_in_previous_window * overlap_percentage)
- Pros:
- Smoothes out traffic spikes and largely solves the boundary problem.
- Much more memory-efficient than the Sliding Window Log.
- Cons:
- Not 100% accurate. It's an approximation, but as Cloudflare noted, the error rate is often extremely low and acceptable for most use cases.
System Architecture & Rule Management
After choosing an algorithm, we need to design the overall system that puts it into practice. This involves deciding where to store counters, how to manage rules, and how the system components interact.
High-Level Architecture
The core idea is to have a centralized, high-speed data store to maintain the counters for our rate-limiting logic.
- Why not a traditional database? Using a SQL/NoSQL database on disk would be far too slow. The latency of disk access would make the rate limiter itself a major performance bottleneck.
- The right tool: In-Memory Cache. An in-memory store like Redis is the ideal choice.
- Speed: It's incredibly fast because all data lives in RAM.
- Helpful Commands: Redis provides atomic commands that are perfect for rate limiting:
INCR: Atomically increments a counter by one.EXPIRE: Sets a time-to-live (TTL) on a key, after which it's automatically deleted. This is perfect for window-based algorithms.
The basic request flow looks like this:
Client -> Rate Limiter Middleware -> Redis (Check & INCR) -> API Server

Managing Rate-Limiting Rules
The system must be flexible enough to support various rules.
- Rule Definition: Rules are typically defined in a human-readable format like YAML or JSON and stored in configuration files. This separates the logic from the code.
- Example (from Lyft):
domain: messaging
descriptors:
- key: message_type
value: marketing
rate_limit:
unit: day
requests_per_unit: 5 - Loading Rules: These configuration files are stored on disk. The rate limiter workers periodically pull these rules and load them into a local cache for fast access. This allows for dynamic rule changes without needing to restart the service.
Handling Throttled Requests: The Client Experience
When a request is blocked, it's crucial to provide clear feedback to the client.
- HTTP Status Code: The standard response is
429 Too Many Requests. - Informative Headers: To help the client behave correctly, the rate limiter should return informative HTTP headers:
X-Ratelimit-Limit: The total number of requests the client can make in a time window.X-Ratelimit-Remaining: The number of requests remaining in the current window.X-Ratelimit-Retry-After: The number of seconds the client should wait before making another request.
This turns the rate limiter from a black box into a predictable system that developers can easily work with.
Distributed Systems Challenges & Optimizations
Building a rate limiter for a single server is straightforward. The real complexity emerges when scaling it to a distributed environment. This section covers the key challenges and advanced optimizations.
Challenge 1: Race Conditions
In a highly concurrent environment, multiple requests can try to update the same counter simultaneously, leading to incorrect counts.

- The Problem:
- Request A reads
countervalue (e.g.,3) from Redis. - Request B reads the same
countervalue (3) before A has updated it. - Request A calculates
3 + 1 = 4and writes4back to Redis. - Request B also calculates
3 + 1 = 4and writes4back to Redis. - Result: The counter should be
5, but it's incorrectly set to4. Two requests were processed, but the counter only incremented once.
- Request A reads
- The Solution: The operation must be atomic.
- Bad Solution: Using traditional locks would solve the problem but would drastically slow down the system, making it a bottleneck.
- Good Solution: Use the features of your data store. For Redis, this means using a Lua script. The script can perform multiple commands (e.g., read, compare, and increment) on the Redis server as a single, uninterruptible atomic operation, which completely eliminates race conditions without the overhead of client-side locking.
Challenge 2: Synchronization
When you have multiple rate limiter servers (which you will in any large-scale system), you need to ensure they share the same counter data.
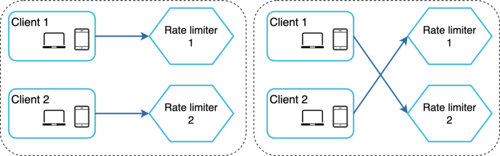
- The Problem: A client's requests can be routed to different servers. If Client A sends a request to Server 1, Server 1 updates its local count. If the next request from Client A goes to Server 2, Server 2 has no knowledge of the first request and the rate limit won't be enforced correctly.
- The Solution: Use a centralized data store (like our Redis cluster).
- Bad Solution: Using "sticky sessions" (where a client is always routed to the same server) is not a good approach. It makes the system stateful, harder to scale, and not fault-tolerant (if that one server goes down, the client's session is lost).
- Good Solution: All servers, regardless of which one a client hits, communicate with the same central Redis cluster to read and update counters. This keeps the servers stateless and the system scalable and resilient.
Performance Optimization for Global Scale
-
Multi-Data Center / Edge Setup: To serve a global user base, you can't have a single Redis cluster in one region. The network latency would be too high for users far away. The solution is to deploy rate limiter instances at various edge locations around the world. Users are routed to the nearest edge server, which provides a low-latency response.
-
Eventual Consistency: With many edge locations, how do you sync the counters for a global limit? The answer is to trade a small amount of accuracy for a large gain in performance and availability.
- Each edge location can track counts locally.
- This data is then synchronized asynchronously in the background.
- This means a user might briefly exceed the global limit by a small margin, but the system remains fast and available. For most rate-limiting use cases, this is an excellent and necessary trade-off.
Monitoring
After deployment, it's crucial to monitor the rate limiter's effectiveness.
- Key Metrics: Track how many requests are being allowed vs. throttled for different rules.
- Goal: The data helps you answer important questions. Are the rules too strict, blocking valid users? Are they too loose, failing to protect the servers during traffic spikes? Is the chosen algorithm behaving as expected? Monitoring allows you to fine-tune the system over time.
Wrap-Up & Further Discussion
To conclude, we've walked through the entire process of designing a robust, distributed rate limiter. We started with requirements, explored architectural placements, dived deep into core algorithms, and tackled the challenges of building for a distributed environment.
Summary of Algorithms Discussed
- Token Bucket: Flexible and allows bursts. Great for user-facing features.
- Leaky Bucket: Enforces a strict, stable outflow rate. Ideal for protecting services that require steady processing.
- Fixed Window Counter: Simple but has an edge-boundary flaw.
- Sliding Window Log: Highly accurate but memory-intensive.
- Sliding Window Counter: A balanced hybrid, offering good accuracy with much lower memory cost.
Additional Talking Points
To demonstrate a broader understanding, consider these advanced topics if time permits in an interview.
1. Hard vs. Soft Rate Limiting
- Hard Rate Limiting: The number of requests cannot exceed the threshold under any circumstances. This is strict and predictable.
- Soft Rate Limiting: Requests can exceed the threshold for a short period. This is more flexible and can be combined with algorithms like the Token Bucket to handle bursts gracefully.
2. Rate Limiting at Different Levels (Defense-in-Depth)
- We primarily discussed rate limiting at the Application Layer (L7) of the OSI model.
- However, it can also be applied at lower levels for broader protection. For example, using
iptableson a Linux server to block traffic from a specific IP address at the Network Layer (L3). This can block malicious traffic before it even reaches your application, saving resources. A comprehensive strategy often involves multiple layers of rate limiting.
3. Best Practices for API Clients
- A good system design discussion also considers the "other side". How should clients interact with a rate-limited API?
- Client-Side Caching: Cache responses to avoid making unnecessary API calls.
- Understand the Limits: A well-behaved client respects the
X-Ratelimit-*headers. - Graceful Error Handling: The client code should anticipate
429errors and handle them without crashing. - Exponential Backoff: When a request is throttled, the client should wait before retrying, and the retry delay should increase exponentially to avoid overwhelming the server (e.g., wait 1s, then 2s, then 4s).
Final Interview Questions for Discussion
Understand the Problem & Establish Design Scope
Can you explain the difference between client-side and server-side rate limiters? Why is the server-side approach generally preferred for security?
When a request is rate-limited, what should the API response look like? What specific HTTP status code and headers would you expect to see?
Let's talk about fault tolerance. Should a rate limiter fail-open or fail-closed? What are the business and technical trade-offs of each approach?
The requirement is to support different throttling rules (by IP, user ID, etc.). From a system design perspective, how would you design the data model for these rules to be flexible and extensible?
High-Level Design - Placement and Architecture
What are the pros and cons of implementing the rate limiter in an API Gateway versus directly within each microservice?
You've joined a team with an existing monolithic application that needs rate limiting. What approach would you recommend and how would you justify it?
If designing a new platform from scratch with dozens of microservices, how would you ensure consistent rate-limiting policies are applied? What role could a service mesh (like Istio or Linkerd) play in this, as opposed to just an API Gateway?
The text mentions 'building your own...takes time.' Beyond just development time, what are the hidden complexities and long-term operational costs of a custom-built rate-limiting service compared to using a managed cloud solution?
Deep Dive into Rate-Limiting Algorithms
What is the key functional difference between the Token Bucket and Leaky Bucket algorithms? For a use case where users might upload a burst of photos at once, which would you choose and why?
Can you explain the 'boundary problem' of the Fixed Window Counter algorithm using a simple example? What simple change could you make to mitigate it, even if it's not perfect?
The Sliding Window Log algorithm is precise but memory-intensive. How would you implement this efficiently in a distributed system using Redis? What specific Redis data structure is ideal for this and why?
Let's compare trade-offs. You need to design a rate limiter for two distinct services: (A) A financial API that processes payments, which can't handle more than 10 transactions/sec. (B) An API for a social media 'like' button. Which algorithm would you lean towards for each, and how would you justify the trade-offs in terms of accuracy, performance, and user experience?
System Architecture & Rule Management
Why is a traditional database like PostgreSQL or MySQL generally a poor choice for storing rate limit counters? What specific characteristics of Redis make it a superior choice here?
A developer is complaining that their application is being rate-limited unexpectedly. What are the first things you would check, and what tools (specifically, HTTP headers) would you tell them to look at to debug the issue on their end?
Let's discuss the rules engine. How would you design the system to allow for dynamic updates to rate-limiting rules—for instance, changing a limit from 100 to 200 requests/minute—without requiring a service restart or a new deployment?
The high-level design shows the middleware making a network call to Redis for every single incoming request. What are the potential performance bottlenecks and failure modes of this design, and how would you start to mitigate them?
Distributed Systems Challenges & Optimizations
Can you explain what a race condition is in the context of a distributed rate limiter? Why can't we just use a simple GET followed by a SET command in Redis to update the counter?
Why is a 'sticky session' approach generally not recommended for ensuring a client interacts with the same rate limiter server? What problems does it create?
The text mentions using a Lua script to solve the race condition. Can you outline, in pseudocode, what this script would do? Why is running a script on the Redis server fundamentally more efficient than, say, using an optimistic locking mechanism managed by the client?
Let's dive into the 'eventual consistency' model for a global rate limiter. Describe a specific business scenario where this model would be a poor choice and you might need to enforce strong consistency, despite the performance cost. What would be the implications for your system architecture?
General & Best Practices
A partner's application is consuming your API. They complain that their app crashes whenever it receives a 429 Too Many Requests error. What specific advice would you give their development team to handle this situation more gracefully?
What is the practical difference between 'hard' and 'soft' rate limiting? Can you provide a real-world use case where a soft limit would be more appropriate than a hard limit?
We've focused on rate limiting at the API Gateway (Layer 7). What are the strategic benefits and potential conflicts of also applying rate limiting at Layer 3 (by IP address) using network tools? How would you design a cohesive defense strategy using both?
When you are designing a new public API for third-party developers, how does the need for rate limiting influence your API's overall design, its documentation, and any SDKs you might provide? How do you balance protecting your service with providing an excellent Developer Experience (DX)?